


I investigate the validity of claims that data prior to 2009 are obsolete for the purpose of trading system development. It is shown that a high proportion of profitable price patterns in more recent daily data maintain their profitability in past data. The results are statistically significant and the claim of prior data obsolescence can be rejected for the conditions of this particular study.
Are historical data prior to 2009 obsolete? As posed, this question is too broad. After all, data is data, and the more data that is available the better it should be in principle when developing trading systems because they are exposed to a wider spectrum of market conditions. However, not all agree with this idea. For example, Dr. Ernie Chan thinks that “we should not use any data prior to 2009 for most analysis” (See ref. 1 below). This view should be expected as different traders have different objectives. It could be the case that for some systems price series dynamics have changed to the extent that using old data makes impossible proper development. Usually, the following reasons are listed by those who claim that data prior to 2000 are obsolete:
- Decimalization of stocks in April of 2001
- Regulation NMS in 2007
- Changes in uptick rules
- Emergence of HFT
The above are valid reasons for not using data before 2000 or 2009 for certain classes of trading strategies. As a matter of fact for my daily calculations of the P-Dow indicator, which by the way has generated some interesting signals recently, I do not use data for Dow stocks prior to 2000. The reason for that is that the signals of this indicator are of short-term nature, maximum 2 to 3 days. Using data prior to 2000, even after detrending is applied, makes the results of this indicator too conservative towards the long side.
It is quite possible that many intraday strategies, including scalping, pairs trading, momentum, as well as some other arbitrage strategies, on both intraday and daily data may have been affected by the changes listed above to the extent that data prior to 2009 or 2000 are obsolete. However, the spectrum of trading strategies is quite broad. Since I concentrate in this blog on parameter-less price patterns, the objective is to investigate whether these changes have caused profitable price patterns to emerge recently that were not profitable in data prior to 2009. The study will concentrate on SPY data.
SPY price series analysis
SPY data from inception (01/29/1993) to 07/02/2015 are split in an in-sample from 01/02/2009 to 07/02/2015 and an out-of-sample from 01/29/1993 to 12/31/2008. Note that the in-sample and out-of-sample are reversed in order and size as compared to normal practice: the in-sample is more recent data and the out-of-sample covers an older time period. Also, normally the out-of-sample is 1/3 of available data but in this case it is about 5/7 of available data.
The two samples with relevant statistics are shown below (Click to enlarge)
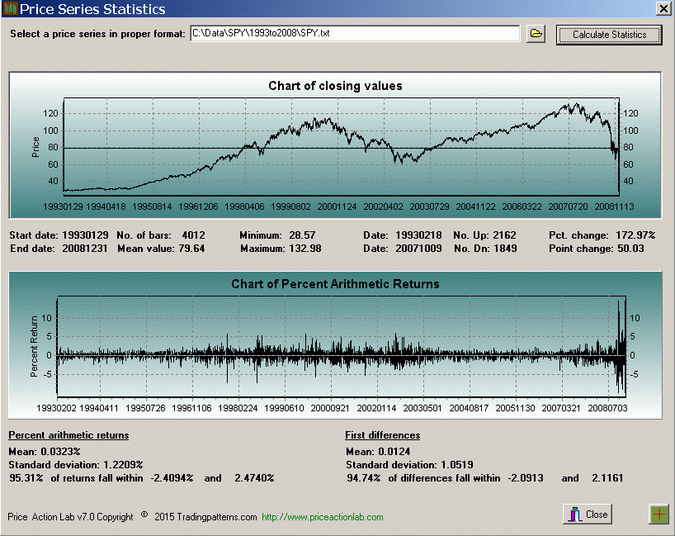 01/29/1993 – 21/31/2008 Click to enlarge |
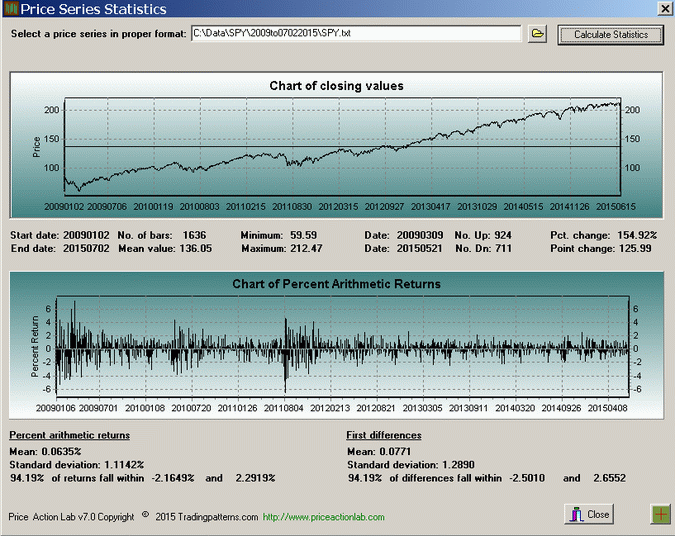 01/02/2009 – 07/02/2015 Click to enlarge |
The analysis shows charts of closing prices during the specified time periods and histograms of daily arithmetic returns. Statistics for both daily arithmetic returns and first differences are provided. Note that the mean of daily arithmetic returns is about double for the in-sample but the standard deviation is about the same. This means that a twice as high return on the average is realized in the in-sample as compared to the out-of-sample (old data) at about the same risk. Is this difference significant enough to claim that there was a major shift in market dynamics?
A statistical test (two-tailed T-test) shows that the null hypothesis of no difference between the two means of arithmetic returns cannot be rejected since the p-value is 0.37. However, one can also look at a more empirical measure, which is the percentage of arithmetic returns that fall inside a two-standard deviation band. In the case of the out-of-sample, 95.31% of returns fall within -2.4% and +2.47%. In the case of the in-sample, and although it visually looks very different, 94.13% of the returns fall within -2.16% and 2.29%. The difference is not significant although the two price series appear to have different dynamics. It is true that during the in-sample there is less risk and higher reward but not to a degree that one can claim that dynamics have changed. Again, let us remember that this analysis applies only to SPY daily data.
In-sample price patterns
I used Price Action Lab to identify profitable short-term price patterns in the in-sample. Note that we are not interested in developing a trading system, as was done in this blog for example where it was already shown that patterns from the out-of-sample perform well in the in-sample (same samples but reversed in that study).
The close of daily bars is used as the predictor Y of price with a maximum look-back period of 9 bars. The minimum win rate for each of the patterns is set to 66%, the minimum profit factor to 1, the minimum number of trades to 19 and the maximum number of consecutive losers to 7. The profit target and stop-loss are set to 2.5% to fall outside the two-standard deviations bands. Below are the results:
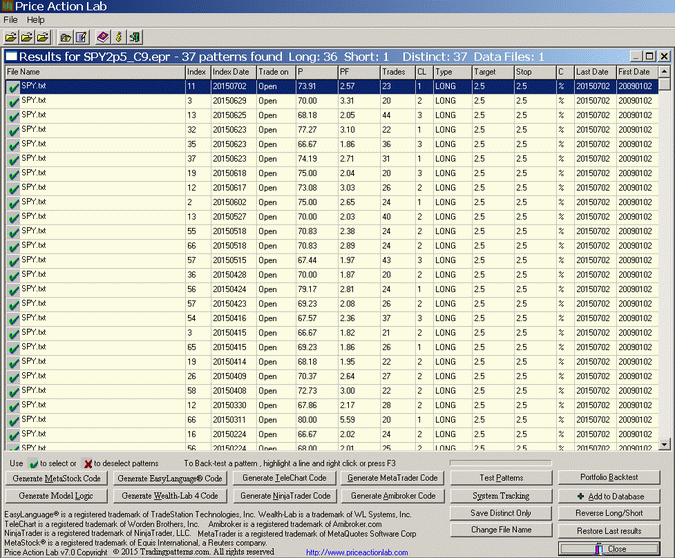
Each line on the results corresponds to a price pattern that satisfies the performance parameters specified by the user. Trade on is the entry point, in this case the Open of next bar. P is the success rate of the pattern, PF is the profit factor, Trades is the number of historical trades, CL is the maximum number of consecutive losers, Type is LONG for long patterns and SHORT for short patterns, Target is the profit target, Stop is the stop-loss and C indicates % or points for the exits, in this case it is %. Last Date and First Date are the last and first date in the historical data file.
PAL identified a total of 27 patterns, 36 long and one short. The large proportion of long patterns was expected due to the strong upward trend.
Next we test the patterns in the out-of-sample. We choose a portfolio backtest on a single security (SPY out-of-sample data) for easier analysis of the results. Thus, if a pattern is profitable, then the portfolio win rate is 100% and the portfolio expectancy E is positive. The results sorted for minimum expectancy port E are shown below:
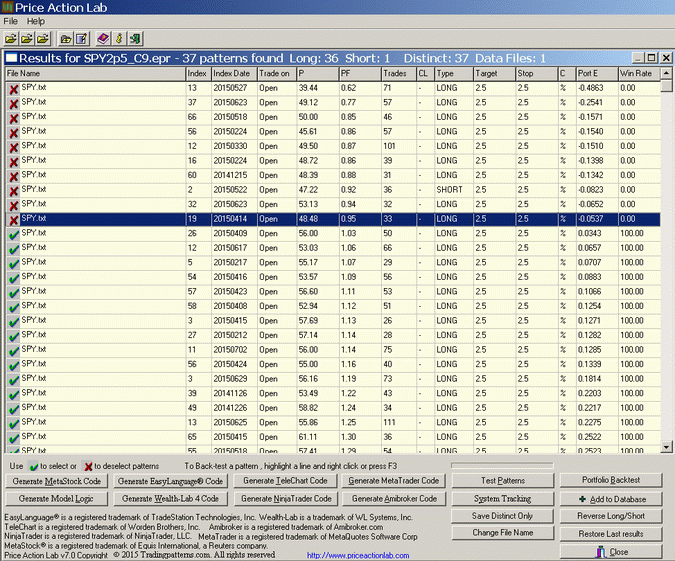
As it turns out, only 10 of the patterns failed in the out-of-sample, i.e., the period from SPY inception to 12/31/2008. This is initial confirmation that changes in the dynamics of the price series, if any, has not given rise two formations that were largely different from the past. The failed patterns are shown on the above results having a negative expectation Port E. Therefore, 73% of the patterns were profitable in the out-of-sample. Below are the equity curves in the two samples that show the combined profit of all trades generated by the patterns:
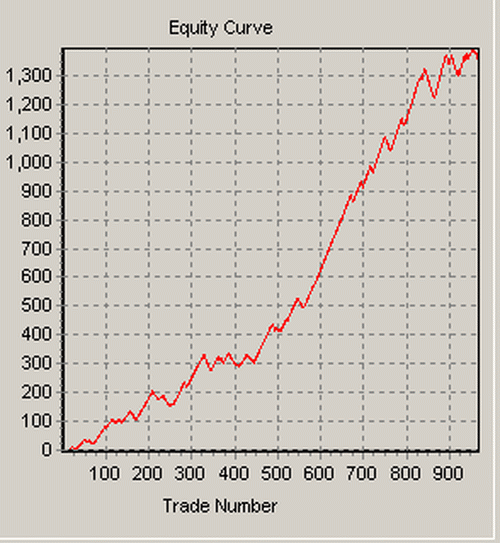 In-sample profit of all patterns |
 Out-of-sample profit of all patterns |
Remember that we are not designing a trading system but we are only looking at the performance of individual patterns. Naturally, the equity curve in the in-sample is smoother than that in the out-of-sample but still the profit in the latter is significant despite the equity swings.
Are the results significant or random? It could be the case that 73% of patterns survived in out-of-sample by luck alone. We can test the hypothesis that the patterns were a random selection from same population and not a special group. In order to perform this hypothesis test we need a larger sample of patterns. We obtain such a sample by applying a Deep search in the in-sample that involves many more predictors of price besides a vector of closing prices. Below are the results for the same search parameters:

In this extended case, 350 patterns were found, 339 long and 11 short. A portfolio backtest in the out-of-sample will show that 152 of the patterns failed. Therefore, the proportion of profitable numbers is about 56%. We could consider the 350 patterns as a representative sample of the population of patterns and perform a hypothesis test. As it turns out, the null hypothesis that the first sample of 37 patterns was random cannot be rejected as the p-value comes out to about 0.2. Therefore, we can say that the 37 patterns that were identified using the closing price as a predictor were not special or that they were selected by chance with high probability and as a result, any change in price dynamics has not given rise to significantly new pattern formations that were unprofitable in the past.
Conclusion
The results of this study are limited to price patterns in daily data. Those who argue that changes in price data after 2009 have rendered older data obsolete may be correct in their domain of application. This adds another important dimension to the already difficult task of trading system development: developers must analyze their systems for susceptibility to changing market conditions and make sure the proper price series are used in backtests when developing them. This problem also makes results from machine learning programs more dubious as all systems are tested in the same in-sample and out-of-sample regardless of whether or not that is appropriate. Thus, in addition to a large data-mining bias there may be bias due to price series dynamics changes when these changes affects the particular systems.
Ref 1. Quantitative Trading Blog
You can subscribe here to notifications of new posts by email.
© 2015 Michael Harris. All Rights Reserved. We grant a revocable permission to create a hyperlink to this blog subject to certain terms and conditions. Any unauthorized copy, reproduction, distribution, publication, display, modification, or transmission of any part of this blog is strictly prohibited without prior written permission.




Friendly Pedant
Data are plural. So "data are data …" The singular is 'datum'.
Your Friendly Pedant.
Sarids
Hello Mike,
This article is interesting. I still confuse about "We could consider the 350 patterns as a representative sample of the population of patterns and perform a hypothesis test. As it turns out, the null hypothesis that the first sample of 37 patterns was random cannot be rejected as the p-value comes out to about 0.2."
1. You said predictor Y of price with a maximum look-back period of 9 bars. Is it also deep search ? Why do you have fewer patterns ?
2. How do you perform a hypothesis test ? please explain more clearly.
Kind Regards,
Sarids
Michael Harris
Hello Sarids,
1. For the first sample I used "Close" in PAL. For the larger sample I used "Deep".
2. It is a standard Chi squared test. We are testing whether the observed difference in the proportion of patterns that were profitable is significant. If p-value > 0.05 the null hypothesis cannot be rejected and the difference is not significant.
Michael
Sarids
Hello Mike,
Can I use this kind of method to create a trading system for stocks that have been active in recent years (2009-2015), but had flat price earlier ? I have an opinion to use recent data as an in-sample, and this article ensure my thought.
Also, I would like to know which method to select the patterns in order to use them in forward test. For example, I should use all patterns that pass criteria of in-sample ( 37 patterns in this article) or I should use only patterns that pass the criteria of out-sample ( 10 patterns in this article ).
Kind Regards,
Sarids
Michael Harris
Hello Sarids,
As I mentioned in the article, this was not presented as a way of developing trading system but of investigating price series dynamics in relation to price patterns.
For the questions you are having about PAL it is better to contact support. Thanks.
Michael
James
Interesting article and subject in general. My thoughts are that there are many price dynamics / market regimes of differening durations that overlap one another. The price dynamics that have existed at least from 1990 to date may not be the most profitable, but they tend to just keep on working.
Out of curiosity, I've done modeling explorations using 2 years of data for model construction between 1990 and 2000 (varying start/end dates) and have been amazed to see the models continue to work up to date in a very consistent manner. Again, these are not super performers. I prefer consistency over highly profitable, but short-lived models.
Kind Regards,
James
Michael Harris
Hello James,
I have seen the same with models developed on data from that period you mentioned. Your point about highly profitable but short-lived is excellent. I think that some fund managers under the pressure of short-term gains to attract capital sacrifice consistency for short-lived profitability. I recall this fund operated by a quant that totally crashed after a couple years of stellar performance because the models were fitted to specific conditions.
Michael
Alessandro
Hello Mr. Harris,
Your software looks interesting to me. I am a Tradestation user. What sort of code will your program generate that I can use?
Thank you.
Alessandro
Michael Harris
Hello Alessandro,
The program generates code for individual price patterns as well as systems of price patterns.
Michael