


DLPAL PRO’s advanced capabilities are used to implement a long/short ETF strategy. We present the flow and examples of historical attribute, test/train and scoring files. A Binary Logistic Regression classifier is used to obtain the final results.
Objective: Implement a long/short strategy based on a universe of 30 liquid ETFs. Timeframe is daily. ETF EOD data since inception are required.
Below is a diagram of the flow:
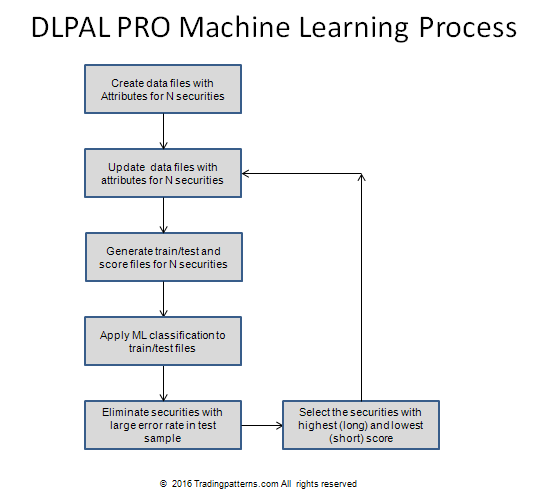
Step 1: Create data files with attributes for all ETFs.
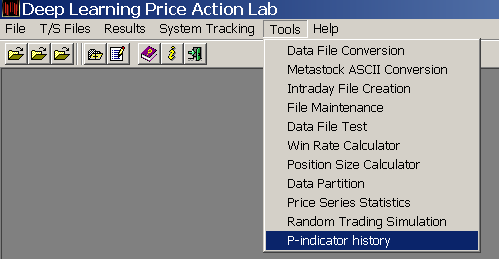
We elect to generate historical files with 750 instances (daily bars.) From DLPAL PRO v2.0 Tools we select P-indicator history:
Next, we specify the parameters for the generation of the attributes, as follows:
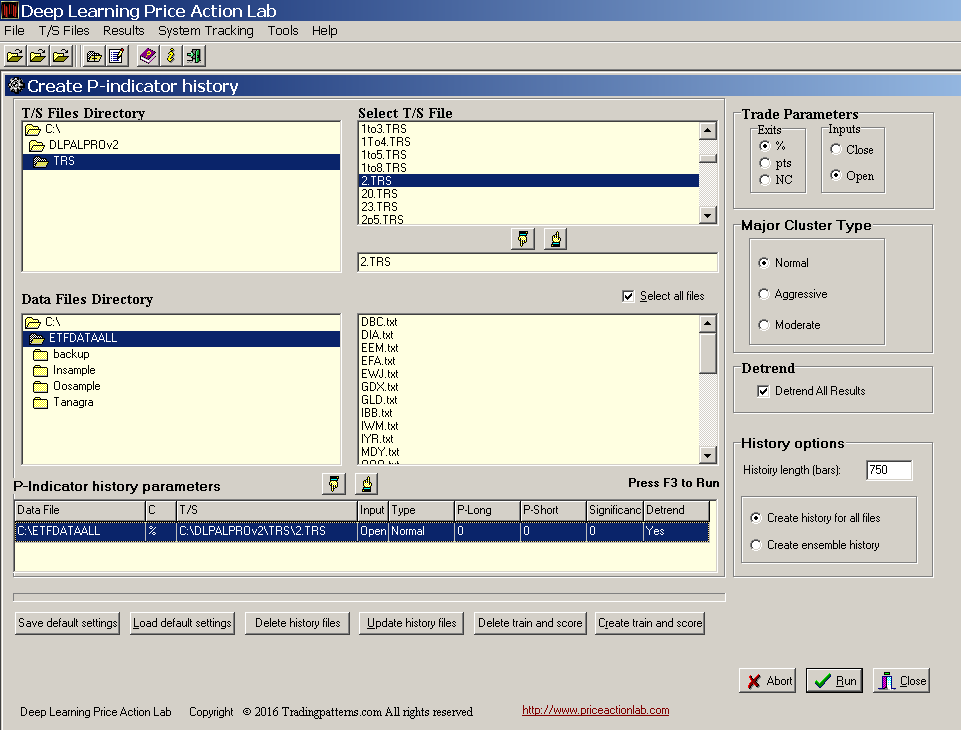
We select the directory of the historical data for the 30 ETFs, the target and stop (2% in this case for both), the trade exit type and entry (% and open), the major cluster type (normal) and we also elect to have the results adjusted for trend because we are interested in short-term trading. We specify that we need the program to generate a history length of 750 bars (instances) and create history for all files in the data directory.
Note that this step takes time to complete but it is done only once. Then the files can be updates in a matter of a few seconds as new data are added. It took a few hours to generate the files with the historical values of the attributes for all 30 ETFs. Below is an example of a few lines for QQQ:
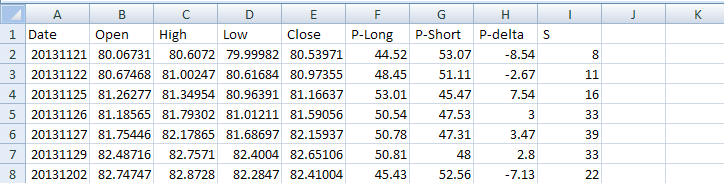
The first date in all files is 20131121 and the last date is 11/11/2016. The four attributes of relevance to machine learning are P-Long and P-short, the long and short directional bias, respectively, P-delta, which is the difference of the first two, and S, the significance of the bias.
Updating historical attribute files
The next step is to update the historical files in case there was new data since the start of their generation. In this case there is no need for an update but it takes a second or two for all 30 ETF files.
Generate train/test and scoring files for all ETFs
This is automatic and takes just a couple of seconds. The target is the sign of the forward 1-period return, 1 if it is positive and 0 if it is negative.
An example of a train/test file for QQQ is shown below:
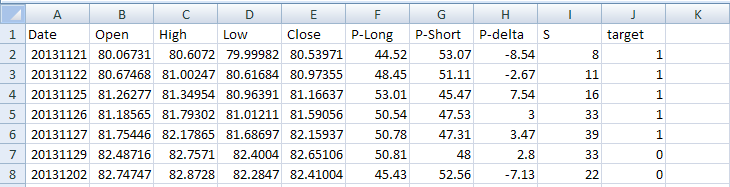
A new column was added, “target” with the binary class 1 or 0. After this is done, the last line in the original historical file has no value for the target because next day’s return is unknown. Actually, this is what we try to forecast using machine learning. Therefore, the last line is not included in the train/test file but in the scoring file, as follows:

The objective of machine leaning is to calculate the probability of class 1 for the target. If it is above 0.5 or some other threshold, this is a long signal and if it is below 0 or some other threshold, it is s short signal.
When all train/test files are generated, we move to the machine learning step.
Apply supervised machine learning
Most quants jump directly to this step without paying too much attention to the quality of attributes they use. Without going into much detail, the edge is in the previous steps and if the quality of the attributes is high and they have economic value for the type of trading strategy considered, then machine learning is the easier part. But when one hears of quants spending a lot of effort tweaking machine leaning algorithms to get a desired result, then there may be no signal in the attributes but possibly just noise. The value of DLPAL PRO is that it generates the data with the attributes. The attributes are unique and have a high signal to noise ratio.
We elect to sample randomly 50% of the instances to train the classifier and then calculate the error in the unused random 50%, which is the test sample. We use Binary Logistic Regression as a first step (via a different platform.) Fancier methods can be used, such as Support Vector Machines and Deep Learning Networks. However, the attributes are already derived using a specific type of deep learning in the first place. If a “simple” classifier cannot do the job, chances of curve-fitting when applying more complex classifiers are high due to the involvement of more parameters. We do not apply any regularization or additional feature (attribute) engineering.
Below are the results from the scoring of all 30 ETFs:
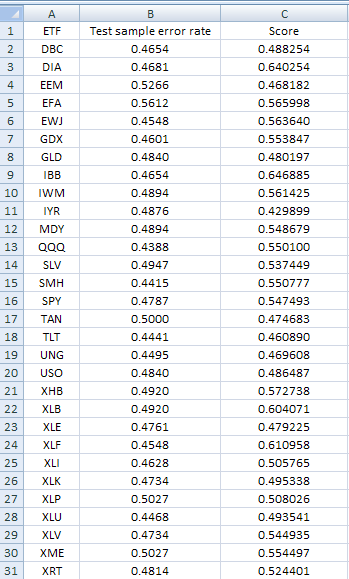
We elect to eliminate ETFs with test error larger than 0.4700. This is the result after applying the filter:
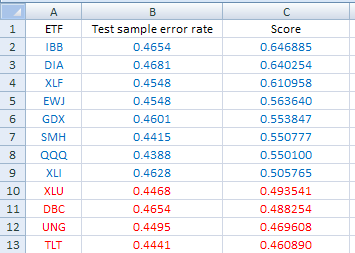
We are left with 9 ETFs to consider for long positions (blue) and 4 for short (red.) We selected DIA, XLF for long and TLT, XLU for short. Note that final selection may depend on other criteria, including volatility considerations, but it can be automated as well.
Repeating the process daily
To repeat the process on a daily basis, one needs to update the original data files for the ETFs (EOD data) and then click “Update history files.” This may take a few seconds. Then clicking “Create train and score” instructs the program to generate those files and that also takes a few seconds.
Summary
We outlined the flow and provided specific examples of how to implement a long/short strategy using DLPAL PRO. This is who sophisticated hedge funds and professionals trade the markets in the 21st century. Their profits come from traders who still use old technical analysis and other random speculators. Profiting from the markets requires staying ahead from the crowd and the methods it applies. Machine learning offers an early entry opportunity for quant traders to profit before the masses catch up, in a way similar to the high profits CTAs made in the 1980s using trend-following, before the rest of the crowd joined. But this style of trading also requires dedication, discipline and a good understanding of quantitative analysis. Sophistication level increases constantly in the markets and no one should expect to profit using outdated styles and methods, especially those developed in mid 20th century.
If you have any questions or comments, happy to connect on Twitter: @priceactionlab
You can download a demo of DLPAL from this link. There is a demo for DLPAL PRO you can download here. For more articles about DLPAL and DLPAL PRO click here.



