


We compare the results of trading strategy development using standard in-sample/out-of-sample method to a walk forward method that involves rebalancing the strategy at the end of each year. We find a significant advantage in using the walk forward method as compared to a static strategy.
Our objective in this article is to compare the results of strategy developed using the standard method of in-sample training/testing followed by out-of-sample validation to a method that rebalances the strategy at the end of each year after the in-sample.
Standard method
We use DLPAL S to develop a strategy for QQQ ETF with in-sample data from 03/10/1999 to 12/30/2011 and then validate it out-of-sample from 01/03/2012 to 08/06/2018. We use profit target and stop-loss of 4%. We employ the extended and the deep clusters of features and we obtain two different strategies, one for each cluster, called INEXT and INDEEP, respectively. The remaining parameters are set as shown in the search workspace below:

Walk Forward Strategy Development (WFSD) method
We start as in standard method with the two strategies, one for the extended and one for the deep cluster. We record the performance for 2012, which is the same for both methods. Then, we repeat the standard method of development by extending the in-sample to 12/31/2012. This means that as new data become available at the end of the year, we then use it to develop a new strategy, one for the extended and one for the deep cluster. This process is repeated at the end of 2013, 2014, 2015, 2016 and 2017. In the WFSD method, the out-of-sample is the next year. The walk forward strategies are called WFSDEXT and WFSDDEEP, for extended and deep cluster, respectively.
Results
Below is a table that compares yearly buy and hold returns to returns obtained using the two methods. TR means Total Return. Click on table to enlarge.
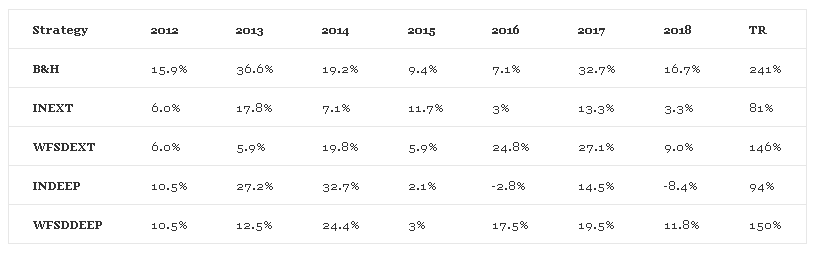
The results are not surprising; the extended and the deep cluster in walk forward mode generate significant results, more than 50% of the total return of the buy and hold. The in-sample/out-of-sample method results are not significant but still confirm the robustness of the data-mining process. Specifically, total return for buy and hold is 241% in the out-of-sample and total returns for walk forward extended and deep are 146% and 160%, respectively.
It should be also noted that in-sample/out-of-sample method results with the Deep cluster are more volatile than those of the extended cluster but the total return is higher, 81% versus 94%, respectively.
Also note that this is an extensive but nevertheless limited study because it involves only one market. However, the important take is that the WFSD method provides a number of strategies that increases with the number of years after the in-sample. This means that after 3 years there are 3 trading strategies available and the trader has a lot more flexibility. For example, a trade may:
- Trade each strategy separately
- Combine the signals of all strategies
- Use only relevant strategies depending on market regime
It is important to realize the strategies work until the market conditions that gave rise to the anomalies they exploit change. Based on market regime analysis, after a number of years, a trader may decide to use only relevant strategies or even restart the whole process from the beginning and move the in-sample forward appropriately. Having a lot of flexibility is an advantage but also challenging.
In the next article we will show you how to use DLPAL S to generate strategies for different market regimes. Recently there has been increased interest to our software from quantitative hedge funds and we believe these articles may serve as a starting ground for more advanced use of the program.



