

The objective of this article is to remind that machine learning is not just science, it is also art. I use as an example the Numerai global artificial intelligence tournament to show that more than half of data science results are random.
The purpose of this article is not to attack Numerai, data science, artificial intelligence or machine learning but instead to show that random results do not only plague classical technical analysis and discretionary trading but also machine learning.
I believe Numerai is a brilliant concept, summarized on their website as follows:
“The most accurate and original machine learning models from the world’s best data scientists are synthesized into a collective artificial intelligence that controls the capital in Numerai’s hedge fund.”
However, at the same time, Numerai provides evidence that machine learning is not only science but also art.
I will show a specific example and you can follow the steps outlined below to test it in the Numerai website. It will allow you to beat more than half of the world’s best data scientists without doing any data science. Note that this does not mean that you should not try to develop a sound model and claim a prize. The sole objective here is to show that there is more to data science than just science.
Below are the five steps to follow:
Step 1: Go to Numerai’s website and download the latest data for the tournament.
Step 2: Ignore the training data completely. There will be no data science.
Step 3: Open the tournament data file. There are 21 feature columns and a t_id column. The objective of the tournament is to use the training data and some machine learning method to develop a model and then estimate the probability of “the observation being of class 1.” This means that for each t_id row we use a model to estimate the probability of class 1.
Step 4: Use the average of features 1 – 21 for the probability estimate, as follows:
W2 = AVERAGE(B2:V2)
Then copy and paste the formula to calculate the values for all W cells.
Step 5: This is the tricky part that requires some knowledge of the scoring mechanism based on log loss function, shown below:
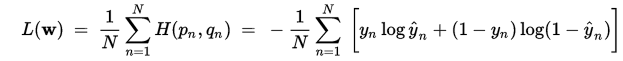
Note that a perfect prediction has log loss 0. The log loss function penalizes confident but wrong estimates of the probability. Since our estimates are essentially random, if we upload the file from Step 4 above it will score near the bottom because it contains many wrong but confident values of the estimated probability in the range of about 0.1 to about 0.8.
We will scale the estimated probabilities derived via averaging the values of the features for each row to lie between 0.49 and 0.51. The formula for that is as follows:
=((0.51-0.49)*(B2-0.106729402)/(0.843236581-0.106729402))+0.49
Repeat this for every cell (copy and paste) in the file. Then delete the original values and leave only the column with the scaled values. Do not forget to label the estimates “probability”. Save and upload.
I named my file MLATION.csv. It ranked No. 168 out of 402 submissions. Therefore, a file with random predictions and with no data science (except some basic understanding of the log loss function) got a higher score than 58% of the world’s best data scientists employing complicated machine learning models. Here is the proof:
![]()
Actually, a higher score that 50% of tournament participants was observed using the last three data sets from Numerai and I expect this to continue in the future because the problem is not with Numerai, or machine learning, but with the way data scientists apply it. When a large sample of data scientists is available, it will reveal that application of data science is not trivial and it is more than science, it is also art.
I have uploaded another MLATION.csv file with estimates from a model I used and it ranked 128 out of 409. I spent only a few hours working on it. The top scores come from people who are either experts in data science and maybe from some that have figured out a way to game the contest. However, I believe it is worthwhile trying. But participants who are new to data science must be aware that in addition to algos there is a need for a lot of additional work in understanding the problem and the data. For example, feature engineering is a tough job but it is also art.
I hope you enjoyed this article.
Enjoy Labor Day Holiday!.
Subscribe via RSS or Email, or follow us on Twitter.
Technical and quantitative analysis of Dow-30 stocks and 30 popular ETFs is included in our Weekly Premium Report. Market signals for longer-term traders are offered by our premium Market Signals service.



