

One would think that by backtesting more ideas and more frequently, the chances of discovering an edge increase. However, the opposite happens, and the chances of discovering something of value diminish with frequent backtesting.
If you believe this is counterintuitive, you could try to think about it differently: If the frequency of backtesting made a difference in discovering an edge, then all those traders who struggle with machine learning algorithms would instead be rich. So what is the process that turns frequent backtesting into an exercise in futility?
The answer is data-mining bias. As a trading system developer tests more ideas, new or modified, data-mining bias increases, and at some point, it becomes so large that the probability of discovering a true edge via backtesting gets close to zero. This counter-intuitive notion that the frequent use of backtesting decreases the chances of success is illustrated in the figure below:
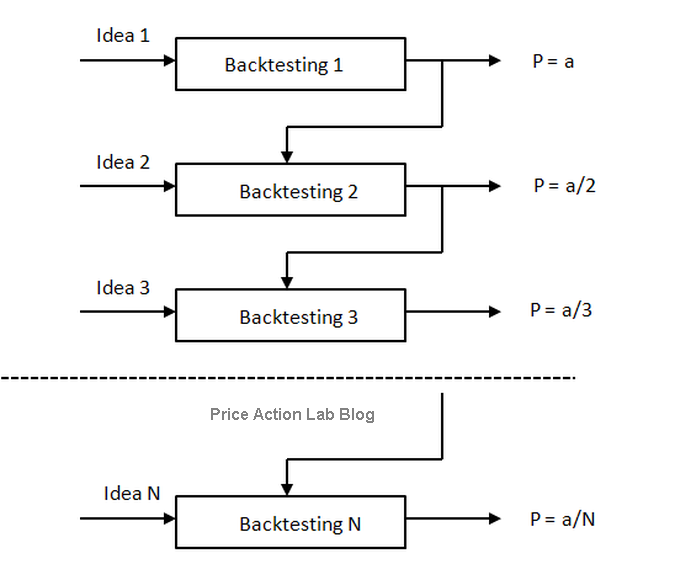
Probability P of discovering an edge as a function of backtesting trials N
In the above figure, “a” is in general a non-linear function of N and of other parameters that assumes a value of less or equal to 1. This means that the probability P tends to 0 as N becomes large. Essentially, those who backtest constantly have very low chances of finding an edge. This includes machine learning programs that mine data relentlessly until something is over-fitted in the in-sample and curve-fitted in the out-of-sample by chance (See this article for more details.)
The conclusion is that traders should use backtesting only when there is a good idea to test. The idea must be as unique as possible. Then, the objective should be to try to debunk it, not prove that it is good by adding more filters and conditions. One of the fundamental problems for users of backtesting is that they try to prove that an idea is good when they should be trying exactly the opposite. The reason for this, which is also a counter-intuitive notion, is that there are very few edges, and the probability that any one idea you backtest is a fluke is close to 1 to start with.
So how can we deal with the paradox of the elusive market edge? One way out is by using backtesting only when there is a unique idea that is unlikely to have been found by others. This is hard but possible. The other remedy when data-mining is used often is by using more advanced tests that minimize data-mining bias instead of trying to estimate it. In general, data-mining bias cannot be estimated because both the real number of trials and its sources are unknown.
These and other facts about backtesting that are rarely or never discussed, along with specific rules and examples of how to deal with data-mining bias, can be found in my new book.
If you found this article interesting, I invite you to follow this blog via any of these methods: RSS or Email, or follow us on Twitter




Ryan
While I agree with the underlying premise of the post, I think may be missing a trick with the positive side of back testing. If you’re not a long term trader of a particular market or style of trading, then frequent tests will create a feel for the market that you’re working on. This process of emersion allows for a fuller understanding of market dynamics and a richer appreciation of how a particular trading style may or may not be suited for the market under back test review.
Thanks for the post.
Michael Harris
Hello Ryan,
What you say is probably true and maybe another counter-intuitive fact about backtesting in the sense that in the process of trying to discover systematic strats one may become a better discretionary trader. I think this is true but it also depends on the effort put to understand the results of frequent testing.
Best.
Michael
Michael Harris
Hello Bo,
it's one think to write a paper and another to have gone through this for the last 25 years.
What you described is the TSIP (Trading System Inversion Paradox) here:
https://www.priceactionlab.com/Blog/2013/11/the-trading-system-inversion-paradox/
Best.
Michael
Bo
Mike, this is another great post. The paper from Bailey proves the same point but your post is much easier to understand. One way to test an idea is to see whether you could lose money on purpose. That is if you flip the signals, is your strategy performing poorly in a consistent way? Surprisingly more often than not it is really not easy to lose money deliberately.