


In this article we include R code for applying binary logistic regression classification to attribute data generated by DLPAL PRO and scoring a new instance.
In Part Three, we presented the flow and details of how to generate historical attribute (features) files for 30 ETFs for the purpose of developing a long/short strategy.
We have since made minor changes to the attribute labels in train/test and scoring files by removing dashes. For example, a portion of the train/test file for SPY with 750 instances (rows) is shown below:

The last date in the train/test file is 20161117. The scoring file contains the data as of last Friday, November 18, 2016, and has only one instance, as shown below:
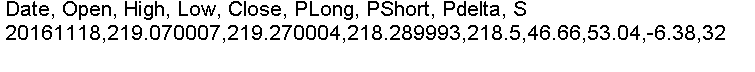
You may have noticed that we have removed the “target” column from scoring files because it is actually not needed and may create problems. These changes are in effect in the program code too.
The objective of supervised classification is to calculate the probability of class 1. This is the probability that SPY will have an up day on Monday, November 21, 2016.
Below is R code for the binary logistic regressions and for the calculation of the probability using the scoring instance.

Note that we selected the attributes PLong, Pshort and Pdelta and they are all significant at the 5% level. The accuracy of the model is 55.57% but it is fitted on the whole sample. In another article we will show how to split the data in train/test samples, train the model and then test it.
The probability based on the new instance is 54.67%. Let us go over the steps:
First, we read the train/test file generated by DLPAL PRO (see part three.)
spydata<-read.table("c:/etfdataall/spy.pit",sep=",",header=T)
attach(spydata)
Then we apply binary logistic regression and get the summary:
model<-glm(target~PLong+PShort+Pdelta,family=binomial(link="logit"))
summary(model)
Then we calculate the model accuracy as follows;
blr.results <- predict(model,spydata,type='response')
blr.results <- ifelse(blr.results > 0.5,1,0)
Error <- mean(blr.results != spydata$target)
print(paste('Accuracy',1-Error))
Finally, we read the scoring file and calculate the probability based on our model:
newdata<-read.table("c:/etfdataall/spy.pis",sep=",",header=T)
predict(model, newdata, type = "response")
This can be repeated for all train/test and scoring files. More advanced code can store the values in a table and sort them to facilitate the long/sort strategy decisions, as shown in part three.
Below is the code:
spydata<-read.table("c:/etfdataall/spy.pit",sep=",",header=T)
attach(spydata)
model<-glm(target~PLong+PShort+Pdelta,family=binomial(link="logit"))
summary(model)
blr.results <- predict(model,spydata,type='response')
blr.results <- ifelse(blr.results > 0.5,1,0)
Error <- mean(blr.results != spydata$target)
print(paste('Accuracy',1-Error))
newdata<-read.table("c:/etfdataall/spy.pis",sep=",",header=T)
predict(model, newdata, type = "response")
As a reminder, machine learning is garbage in, garbage out (GIGO) process. Quality of results depends on the quality of features. The advantage in using DLPAL PRO is its ability to generate high quality features and the files to be used in train/test and scoring. This is a massive job. The classification is the easier part. If there are no high quality features and the accuracy is around 50%, then intense feature engineering only increases data-snooping bias and probability of Type I error (false positive.) Our position is that in financial applications, if binary logistic regression does not generate an acceptable accuracy above 54%, then there is too much noise in the attributes (features.) Fancier classification methods, such as support vector machines or deep learning neural networks should be used only when there is room for improvement.
If you have any questions or comments, happy to connect on Twitter: @priceactionlab
You can download a demo of DLPAL from this link. For more articles about DLPAL and DLPAL PRO click here.



