

In the last few days there were several posts in financial social media to a number of new articles about backtesting. While the articles are good for just beginners, the message when it comes to backtesting is to refrain from it as much as possible.
The following excerpt is from my book Fooled by Technical Analysis: The perils of charting, backtesting and data-mining – Chapter Six,
By the late 1980s the first backtesting software packages became available for sale to retail traders. One of the first such programs was System Writer Plus by Omega Research, Inc., a company that in the late 1990s changed its name to Tradestation Technologies. System Writer Plus offered a high level trading language, called EasyLanguage, that one could use to code trading ideas and test them on a large database of historical data that came with the program.
Backtesting revolutionized the trading industry and offered retail traders a powerful analysis tool. Early quants used the tool to quickly identify price action anomalies and profit from them. During that time it was amazing what one could discover in price series that actually made money.
However, as more people started using these programs and more became available, the opportunities one could find started decreasing fast due to arbitrage and crowding effects. Even known anomalies, such as price series momentum, started to get affected and traders had to increase the period of the fast and slow moving averages to remain profitable.
Many still do not realize the impact of backtesting in making markets more efficient and at the same time increasing failure rates of retail quant traders.
Briefly, the problem with backtesting is data-mining bias. This is another excerpt from the same book and chapter as above:
Data-mining is a dangerous practice because as the number of trials to find an edge increase, the probability of accepting a model that possesses no market timing ability but performs well in the out-of-sample just by chance tends to 1 and after a while it becomes the certain event.
The chart below from the blog article Counter-intuitive Fact About Backtesting summarizes the perils of backtesting.
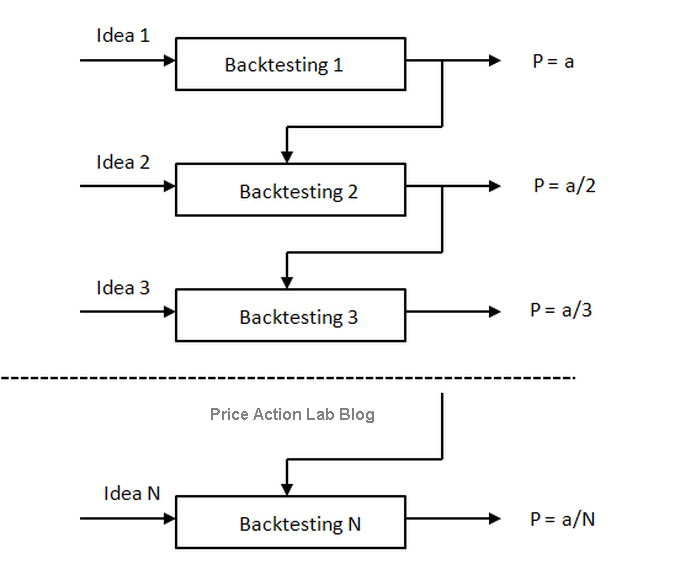
P is the probability of finding a valid model when one starts backtesting. As the number of trials N increases, the probability P goes to zero.
Academics and others have proposed ways of minimizing data-mining bias or even correcting for it but most of these are exercises in futility. The message is:
Backtest less
Backtest only when you think you have a good idea that is unique. This is the only practical and robust way of minimizing data mining bias. Most of the methods proposed for doing that are of questionable effectiveness.
In case data-mining algos are used to identify models from data, then the bias is large but certain practices may be used may reduce it significantly. Some of these are listed in this article. Briefly, below are some practical guidelines:
- Underline process that generates the models must be deterministic
- Use the out-of-sample only once and if there is failure do not use it again.
- Reduce number of model parameters (indicators, patterns, etc.)
- Use only similar predictors or features in machine learning.
Backtesting if not done properly is as dangerous as generating random trades with a fair coin and often with a worse-than-random coin.
More details and specific examples can be found in Chapter 6 of the book, Fooled By Technical Analysis.
© 2012 – 2020 Michael Harris. All Rights Reserved. We grant a revocable permission to create a hyperlink to this blog subject to certain terms and conditions. Any unauthorized copy, reproduction, distribution, publication, display, modification, or transmission of any part of this blog is strictly prohibited without prior written permission.



