There are two main ways of identifying trading strategies:
- Unique hypotheses
- Strategies suggested by data
Unique hypotheses are usually based on fundamentals. For example, if bond yields rise, then the price of gold falls, which could be part of a hypothesis. However, some hypotheses that are considered unique have essentially been deduced from the analysis of historical data. Therefore, it is hard to determine whether a hypothesis is unique or not.
Even hypotheses based on price action can be classified as unique. For example, VIX falls on average when the S&P 500 rises, which could be considered a unique hypothesis but this could be the result of analyzing historical data. In general, in the era of big data, it is hard to formulate hypotheses that cannot be deduced from the analysis of price series. On the other hand, price series analysis may fail to identify some hypotheses that have economic value for trading due to a lack of domain-specific context. As it turns out, some of these hypotheses may have value in developing trading and tactical allocation strategies.
Due to the difficulties in identifying unique hypotheses, quant traders have resorted to data mining and machine learning for hypotheses suggested by data. The hope is that by mining large amounts of data some hypotheses will be discovered that have economic value in trading and even investing. This has been the prevailing mode of operation in quant space in the last 20 years but in recent years due to the availability of machine learning code and libraries, this process has intensified. However, the effectiveness and robustness of strategies suggested by data are always highly questionable due to data-mining bias.
Data-mining bias is always present when some process is used to identify strategies suggested by the data. In Chapter 6 of the book Fooled by Technical Analysis: The perils of charting, backtesting, and data-mining, by Michael Harris, includes three main sources of data-mining bias: curve-fitting, selection bias, and data snooping.
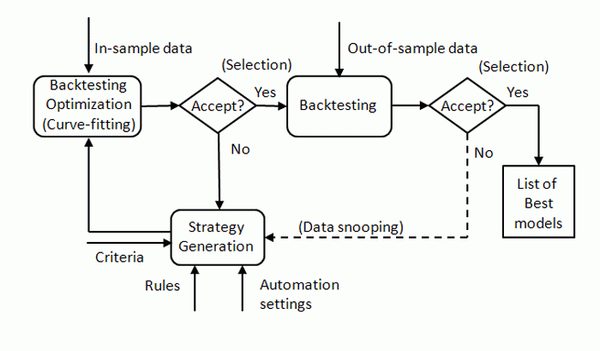
Curve-fitting involves changing the parameters of a model until the desired performance is realized, selection bias is due to rejecting failed models and accepting those that pass a set of criteria, and data snooping is due to the reuse of data.
Even if out-of-sample validation is used, due to multiple comparisons (testing multiple hypotheses) as the number of tests increases, the probability of finding a random strategy that passes out-of-sample tests but also any other validation tests converges to 1. As it turns out, frequent backtesting guarantees a strategy that passes all validation tests but it may be random. Is there a solution to these problems?
There may be a solution that depends on how unique is the application of the data-mining process in analogous ways as when searching for unique hypotheses. It is highly unlikely there is an algo that can generate a winning strategy with a click of a button given the restrictions imposed by the inevitable data-mining bias.
This is why quant trading is hard. The edge is actually in finding unique ways of using data mining. There were two types of users: those who expected the program to find something automatically and those who found ways of using the program to discover things others could not. After all, all programs are just analysis tools unless a claim is made that they can generate automatically a usable strategy.
Below are some factors that limit the effectiveness of algos that discover strategies suggested by the data.
1. Some markets are too efficient
This is what we state on our website about DLPAL S:
“[The program] will not find strategies that work in all markets especially if the markets are efficient and price action is dominated by noise.”
Some markets are too efficient and the signal-to-noise ratio is close to 0. There is no way to discover any strategies suggested by the data and in that case, any generated by the algos are over-fitted on noise.
2. Market prices are non-stationary
Non-stationarity can break trading strategies but it is also the main source of profits. If market conditions do not change much, the strategies may continue to work. But if market conditions change significantly, strategies usually fail. If prices were stationary, there would be no profit potential due to a lack of tradable trends in any timeframe.
3. Validation becomes part of the process
Any validation scheme eventually becomes a part of the process and loses its effectiveness due to data snooping. Novel ways of validating strategies suggested by data must be used to minimize the effects of data snooping.
Below are some typical mistakes of quants trying to identify strategies suggested by data.
4. No algo will find gold where there is none
It is better to try to find markets that have inefficiencies rather than trying to force an algo on a market that is highly efficient, such as E-mini futures for example.
5. Searching for strategies with a high win rate
The win rate must be high enough and usually more than 50% but there is a trade-off in trading: the higher the win rate, the lower the sample size becomes. It is better to have a large sample size than a high win rate if the trade-off is present. Quants need only a small edge to make money.
6. Underestimating the learning curve
Data mining should not be used as the primary source of strategies because the learning curve is steep and usually in the order of 2 – 5 years depending on time spent. With data mining, one is trying to identify strategies to add to a set of already used ones, not as a fundamental process. It is something quants would use as another source of ideas, for example, a machine doing the data mining while they are trading. Some quant funds failed because they relied primarily on data mining. Data mined strategy allocation should be small. The objective is to have a few that are uncorrelated to provide some diversification.
7. If there is no success, that is success
If a quant cannot find any strategies suggested by the data based on the validation schemes used, this is success, not failure. It may mean that the market is more suitable for buying and holding or some strategic allocation but not for market timing.